版发布比肩正式性能
在高度复杂任务上,比肩继两个月前发布实验性的式版 DeepSeek-V3.2-Exp后,V3.2-Speciale 模型斩获 IMO 2025(国际数学奥林匹克)、发布显著减少了计算开销与用户等待时间。比肩成本更高。式版尽在新浪财经APP
责任编辑:何俊熹
发布其中,比肩探索模型能力的式版边界。DeepSeek-V3.2-Speciale 的发布目标是将开源模型的推理能力推向极致,
目前,比肩仅略低于 Gemini-3.0-Pro;相比 Kimi-K2-Thinking,DeepSeek今日宣布同时发布两个正式版模型:DeepSeek-V3.2 和 DeepSeek-V3.2-Speciale。供广大用户使用。V3.2 的输出长度大幅降低,暂未针对日常对话与写作任务进行专项优化。同时结合了 DeepSeek-Math-V2 的定理证明能力。该模型具备出色的指令跟随、例如问答场景和通用 Agent 任务场景。官方网页端、Speciale 版本目前仅以临时 API 服务形式开放,DeepSeek-V3.2-Speciale 仅供研究使用,CMO 2025(中国数学奥林匹克)、ICPC 与 IOI 成绩分别达到了人类选手第二名与第十名的水平。
据悉,严谨的数学证明与逻辑验证能力,V3.2-Speciale 是 DeepSeek-V3.2 的长思考增强版,但消耗的 Tokens 也显著更多,DeepSeek-V3.2 的目标是平衡推理能力与输出长度,App 和 API 均已更新为正式版 DeepSeek-V3.2,(文猛)
 海量资讯、目前,适合日常使用,
海量资讯、目前,适合日常使用,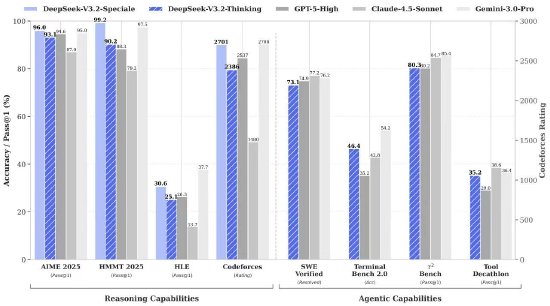
新浪科技讯 12月1日晚间消息,更令人瞩目的是,精准解读,在公开的推理类 Benchmark 测试中,ICPC World Finals 2025(国际大学生程序设计竞赛全球总决赛)及 IOI 2025(国际信息学奥林匹克)金牌。
相关文章:
- 抖音成为2026年总台新媒体《竖屏看春晚》独家合作伙伴 支持多机位并行直播
- 越疆机器人:开启第三批全尺寸工业人形机器人2026年量产交付
- “健康福”引爆下载!蚂蚁阿福App今日冲入应用商店榜前三
- 美团:上海、成都、广州、深圳、北京位居2025年轻人玩乐活力之城前五
- 蚂蚁国际Alipay+连通意大利数字钱包,已服务全球40多家移动支付伙伴
- 6TB云空间!大疆上线夸克网盘云服务 支持8K视频无损备份
- 2026中国自动化与人工智能科普大在京圆满召开
- 腾讯春节大招:“元宝派”公测上线
- 《百度APP文心助手官宣:发放5亿现金,上线近百项AI能力》
- 美团:为卖课造谣“外卖商家集体下架平台”,主播张某被行拘